Overview
- Add your training files to Encord.
- Create a Benchmark Project Establish ground truth labels by having a trusted expert annotate the data. You must complete this Project before annotator training begins.
- Set up Annotator Training Projects You must create one training Project per annotator. Use the same Dataset as the Benchmark Project in each annotator training Project. Annotators label the data, and their work is compared against the gold standard created in the benchmark.
- Annotators Label Training Tasks Annotators must complete all the training tasks assigned to them.
- Evaluate Annotator Performance Use the provided SDK script to compare annotator labels with the benchmark. Analyze the results to assess accuracy and provide targeted feedback.
STEP 1: Add Files to Encord
You must first add your data to Encord. These files are used to train your annotators.1
Create a Cloud Integration
2
Create a Folder to Store your Files
- Navigate to Data > Files & Folders
- Click the + New folder button to create a new folder. Select the type of folder you want to create.
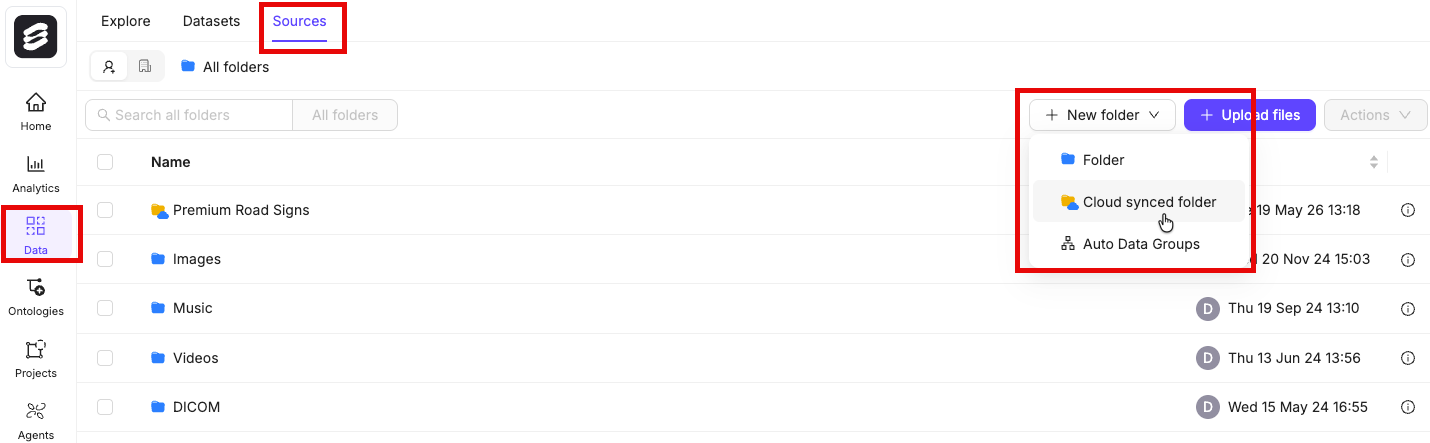
- Give the folder a meaningful name and description.
- Click Create to create the folder. The folder is listed in Files & Folders.
3
Create JSON file for Registration
To register files from cloud storage into Encord, you must create a JSON file specifying the files you want to upload.All types of data (videos, images, image groups, image sequences, and DICOM) from a private cloud are added to a Dataset in the same way, by using a JSON or CSV file. The file includes links to all images, image groups, videos and DICOM files in your cloud storage.
While you can use a CSV file, we strongly recommend using JSON files for uploading cloud data to Encord for better compatibility and performance.
For a list of supported file formats for each data type, go here
Encord supports file names up to 300 characters in length for any file or video for upload.
Encord enforces the following upload limits for each JSON file used for file registration:
- Up to 1 million URLs
- A maximum of 500,000 items (e.g. images, image groups, videos, DICOMs)
- URLs can be up to 16 KB in size
JSON Format
JSON Format
For detailed information about the JSON file format used for import go here.The information provided about each of the following data types is designed to get you up and running as quickly as possible without going too deeply into the why or how. Look at the template for each data type, then the examples, and adjust the examples to suit your needs.
Template: Provides the proper JSON format to import image groups into Encord.Examples:
Template: Provides the proper JSON format to import image groups into Encord.Examples:
The following is an example JSON for uploading three DICOM series belonging to a study. Each title and object URL correspond to individual DICOM series.
Template: Provides the proper JSON format to import image groups into Encord.Examples:
Template: Provides the proper JSON format to import image groups into Encord.Examples:
The following is an example JSON for uploading three DICOM series belonging to a study. Each title and object URL correspond to individual DICOM series.
Template: Provides the proper JSON format to import image groups into Encord.Examples:
Template: Provides the proper JSON format to import image groups into Encord.Examples:
The following is an example JSON for uploading three DICOM series belonging to a study. Each title and object URL correspond to individual DICOM series.
Template: Provides the proper JSON format to import image groups into Encord.Examples:
Template: Provides the proper JSON format to import image groups into Encord.Examples:
The following is an example JSON for uploading three DICOM series belonging to a study. Each title and object URL correspond to individual DICOM series.
If
skip_duplicate_urls is set to true, all object URLs that exactly match existing images/videos in the dataset are skipped.JSON for AWS
JSON for AWS
Audio files
Audio files
Audio Files
The following is an example JSON file for uploading two audio files to Encord.- Template: Imports audio files with an Encord title.
- Audio Metadata: Imports one audio file with the
audiometadataflag. When theaudiometadataflag is present in the JSON file, we directly use the supplied metadata without performing any additional validation, and do not store the file on our servers. To guarantee accurate labels, it is crucial that the metadata you provide is accurate.
Text Files
Text Files
Single images
Single images
Single Images
For detailed information about the JSON file format used for import go here.The JSON structure for single images parallels that of videos.Template: Provides the proper JSON format to import images into Encord.Examples:- Data Imports the images only.
Image groups
Image groups
Image groups
For detailed information about the JSON file format used for import go here.- Image groups are collections of images that are processed as one annotation task.
- Images within image groups remain unaltered, meaning that images of different sizes and resolutions can form an image group without the loss of data.
- Image groups do NOT require ‘write’ permissions to your cloud storage.
- If
skip_duplicate_urlsis set totrue, all URLs exactly matching existing image groups in the dataset are skipped.
The position of each image within the sequence needs to be specified in the key (
objectUrl_{position_number}).- Data: Imports the image groups only.
Image sequences
Image sequences
Image sequences
For detailed information about the JSON file format used for import go here.- Image sequences are collections of images that are processed as one annotation task and represented as a video.
- Images within image sequences may be altered as images of varying sizes and resolutions are made to match that of the first image in the sequence.
- Creating Image sequences from cloud storage requires ‘write’ permissions, as new files have to be created in order to be read as a video.
- Each object in the
image_groupsarray with thecreateVideoflag set totruerepresents a single image sequence. - If
skip_duplicate_urlsis set totrue, all URLs exactly matching existing image sequences in the dataset are skipped.
The position of each image within the sequence needs to be specified in the key (
objectUrl_{position_number}).Encord supports up to 32,767 entries (21:50 minutes) for a single image sequence. We recommend up to 10,000 to 15,000 entries for a single image sequence for best performance. If you need a longer sequence, we recommend using video instead of an image sequence.
- Data: Imports the images groups only.
DICOM
DICOM
DICOM
For detailed information about the JSON file format used for import go here.- Each
dicom_serieselement can contain one or more DICOM series. - Each series requires a title and at least one object URL, as shown in the example below.
- If
skip_duplicate_urlsis set totrue, all object URLs exactly matching existing DICOM files in the dataset will be skipped.
Custom metadata is distinct from patient metadata, which is included in the
.dcm file and does not have to be specific during the upload to Encord. - The first series contains only a single object URL, as it is composed of a single file.
- The second series contains 3 object URLs, as it is composed of three separate files.
- The third series contains 2 object URLs, as it is composed of two separate files.
For each DICOM upload, an additional
DicomSeries file is created. This file represents the series file-set. Only DicomSeries are displayed in the Encord application.Template
Multiple file types
Multiple file types
You can upload multiple file types using a single JSON file. The example below shows 1 image, 2 videos, 2 image sequences, and 1 image group.
Multiple file types
JSON for GCP
JSON for GCP
Audio files
Audio files
Audio Files
The following is an example JSON file for uploading two audio files to Encord.- Example 1 imports audio files with an Encord title.
- Example 2 imports one audio file with the
audiometadataflag. When theaudiometadataflag is present in the JSON file, we directly use the supplied metadata without performing any additional validation, and do not store the file on our servers. To guarantee accurate labels, it is crucial that the metadata you provide is accurate.
Text Files
Text Files
Single images
Single images
Single Images
For detailed information about the JSON file format used for import go here.The JSON structure for single images parallels that of videos.Template: Provides the proper JSON format to import images into Encord.Examples:- Data Imports the images only.
- Image Metadata: Imports images with image metadata. This improves the import speed for your images.
Image groups
Image groups
Image groups
For detailed information about the JSON file format used for import go here.- Image groups are collections of images that are processed as one annotation task.
- Images within image groups remain unaltered, meaning that images of different sizes and resolutions can form an image group without the loss of data.
- Image groups do NOT require ‘write’ permissions to your cloud storage.
- If
skip_duplicate_urlsis set totrue, all URLs exactly matching existing image groups in the dataset are skipped.
The position of each image within the sequence needs to be specified in the key (
objectUrl_{position_number}).- Data: Imports the image groups only.
Image sequences
Image sequences
Image sequences
For detailed information about the JSON file format used for import go here.- Image sequences are collections of images that are processed as one annotation task and represented as a video.
- Images within image sequences may be altered as images of varying sizes and resolutions are made to match that of the first image in the sequence.
- Creating Image sequences from cloud storage requires ‘write’ permissions, as new files have to be created in order to be read as a video.
- Each object in the
image_groupsarray with thecreateVideoflag set totruerepresents a single image sequence. - If
skip_duplicate_urlsis set totrue, all URLs exactly matching existing image sequences in the dataset are skipped.
The position of each image within the sequence needs to be specified in the key (
objectUrl_{position_number}).Encord supports up to 32,767 entries (21:50 minutes) for a single image sequence. We recommend up to 10,000 to 15,000 entries for a single image sequence for best performance. If you need a longer sequence, we recommend using video instead of an image sequence.
- Data: Imports the images groups only.
DICOM
DICOM
DICOM
For detailed information about the JSON file format used for import go here.- Each
dicom_serieselement can contain one or more DICOM series. - Each series requires a title and at least one object URL, as shown in the example below.
- If
skip_duplicate_urlsis set totrue, all object URLs exactly matching existing DICOM files in the dataset will be skipped.
Custom metadata is distinct from patient metadata, which is included in the
.dcm file and does not have to be specific during the upload to Encord. - The first series contains only a single object URL, as it is composed of a single file.
- The second series contains 3 object URLs, as it is composed of three separate files.
- The third series contains 2 object URLs, as it is composed of two separate files.
For each DICOM upload, an additional
DicomSeries file is created. This file represents the series file-set. Only DicomSeries are displayed in the Encord application.JSON for DICOM
Multiple file types
Multiple file types
You can upload multiple file types using a single JSON file. The example below shows 1 image, 2 videos, 2 image sequences, and 1 image group.
Multiple file types
JSON for Azure
JSON for Azure
Audio files
Audio files
Audio Files
The following is an example JSON file for uploading two audio files to Encord.- Template: Imports audio files with an Encord title.
- Audio Metadata: Imports one audio file with the
audiometadataflag. When theaudiometadataflag is present in the JSON file, we directly use the supplied metadata without performing any additional validation, and do not store the file on our servers. To guarantee accurate labels, it is crucial that the metadata you provide is accurate.
Text Files
Text Files
Single images
Single images
Single Images
For detailed information about the JSON file format used for import go here.The JSON structure for single images parallels that of videos.Template: Provides the proper JSON format to import images into Encord.Examples:- Data Imports the images only.
- Image Metadata: Imports images with image metadata. This improves the import speed for your images.
Image groups
Image groups
Image groups
For detailed information about the JSON file format used for import go here.- Image groups are collections of images that are processed as one annotation task.
- Images within image groups remain unaltered, meaning that images of different sizes and resolutions can form an image group without the loss of data.
- Image groups do NOT require ‘write’ permissions to your cloud storage.
- If
skip_duplicate_urlsis set totrue, all URLs exactly matching existing image groups in the dataset are skipped.
The position of each image within the sequence needs to be specified in the key (
objectUrl_{position_number}).- Data: Imports the image groups only.
Image sequences
Image sequences
Image sequences
For detailed information about the JSON file format used for import go here.- Image sequences are collections of images that are processed as one annotation task and represented as a video.
- Images within image sequences may be altered as images of varying sizes and resolutions are made to match that of the first image in the sequence.
- Creating Image sequences from cloud storage requires ‘write’ permissions, as new files have to be created in order to be read as a video.
- Each object in the
image_groupsarray with thecreateVideoflag set totruerepresents a single image sequence. - If
skip_duplicate_urlsis set totrue, all URLs exactly matching existing image sequences in the dataset are skipped.
The position of each image within the sequence needs to be specified in the key (
objectUrl_{position_number}).Encord supports up to 32,767 entries (21:50 minutes) for a single image sequence. We recommend up to 10,000 to 15,000 entries for a single image sequence for best performance. If you need a longer sequence, we recommend using video instead of an image sequence.
- Data: Imports the images groups only.
DICOM
DICOM
DICOM
For detailed information about the JSON file format used for import go here.- Each
dicom_serieselement can contain one or more DICOM series. - Each series requires a title and at least one object URL, as shown in the example below.
- If
skip_duplicate_urlsis set totrue, all object URLs exactly matching existing DICOM files in the dataset will be skipped.
Custom metadata is distinct from patient metadata, which is included in the
.dcm file and does not have to be specific during the upload to Encord. - The first series contains only a single object URL, as it is composed of a single file.
- The second series contains 3 object URLs, as it is composed of three separate files.
- The third series contains 2 object URLs, as it is composed of two separate files.
For each DICOM upload, an additional
DicomSeries file is created. This file represents the series file-set. Only DicomSeries are displayed in the Encord application.Template
Multiple file types
Multiple file types
You can upload multiple file types using a single JSON file. The example below shows 1 image, 2 videos, 2 image sequences, and 1 image group.
JSON for OTC
JSON for OTC
Audio files
Audio files
Audio Files
The following is an example JSON file for uploading two audio files to Encord.- Template: Imports audio files with an Encord title.
- Audio Metadata: Imports one audio file with the
audiometadataflag. When theaudiometadataflag is present in the JSON file, we directly use the supplied metadata without performing any additional validation, and do not store the file on our servers. To guarantee accurate labels, it is crucial that the metadata you provide is accurate.
Text Files
Text Files
Single images
Single images
Single Images
For detailed information about the JSON file format used for import go here.The JSON structure for single images parallels that of videos.Template: Provides the proper JSON format to import images into Encord.Examples:- Data Imports the images only.
- Image Metadata: Imports images with image metadata. This improves the import speed for your images.
Image groups
Image groups
Image groups
For detailed information about the JSON file format used for import go here.- Image groups are collections of images that are processed as one annotation task.
- Images within image groups remain unaltered, meaning that images of different sizes and resolutions can form an image group without the loss of data.
- Image groups do NOT require ‘write’ permissions to your cloud storage.
- If
skip_duplicate_urlsis set totrue, all URLs exactly matching existing image groups in the dataset are skipped.
The position of each image within the sequence needs to be specified in the key (
objectUrl_{position_number}).- Data: Imports the image groups only.
Image sequences
Image sequences
Image sequences
For detailed information about the JSON file format used for import go here.- Image sequences are collections of images that are processed as one annotation task and represented as a video.
- Images within image sequences may be altered as images of varying sizes and resolutions are made to match that of the first image in the sequence.
- Creating Image sequences from cloud storage requires ‘write’ permissions, as new files have to be created in order to be read as a video.
- Each object in the
image_groupsarray with thecreateVideoflag set totruerepresents a single image sequence. - If
skip_duplicate_urlsis set totrue, all URLs exactly matching existing image sequences in the dataset are skipped.
The position of each image within the sequence needs to be specified in the key (
objectUrl_{position_number}).Encord supports up to 32,767 entries (21:50 minutes) for a single image sequence. We recommend up to 10,000 to 15,000 entries for a single image sequence for best performance. If you need a longer sequence, we recommend using video instead of an image sequence.
- Data: Imports the images groups only.
DICOM
DICOM
DICOM
For detailed information about the JSON file format used for import go here.- Each
dicom_serieselement can contain one or more DICOM series. - Each series requires a title and at least one object URL, as shown in the example below.
- If
skip_duplicate_urlsis set totrue, all object URLs exactly matching existing DICOM files in the dataset will be skipped.
Custom metadata is distinct from patient metadata, which is included in the
.dcm file and does not have to be specific during the upload to Encord. - The first series contains only a single object URL, as it is composed of a single file.
- The second series contains 3 object URLs, as it is composed of three separate files.
- The third series contains 2 object URLs, as it is composed of two separate files.
For each DICOM upload, an additional
DicomSeries file is created. This file represents the series file-set. Only DicomSeries are displayed in the Encord application.JSON for DICOM
Multiple file types
Multiple file types
You can upload multiple file types using a single JSON file. The example below shows 1 image, 2 videos, 2 image sequences, and 1 image group.
Multiple file types
JSON for AWS Multi-Region Access Point
JSON for AWS Multi-Region Access Point
When using a Multi-Region Access Point for your AWS S3 buckets the JSON file has to be slightly different from the examples provided. Instead of an object’s URL, objects are specified using the ARN of the Multi-Region Access Point followed by the object name. The example below shows how video files from a Multi-Region Access Point would be specified.
MRAP Example
4
Import your Files

Import local data
Import local data
- Navigate to Data > Files & Folders in the Encord platform.
- Click into a Folder.
- Click + Upload files. A dialog appears.
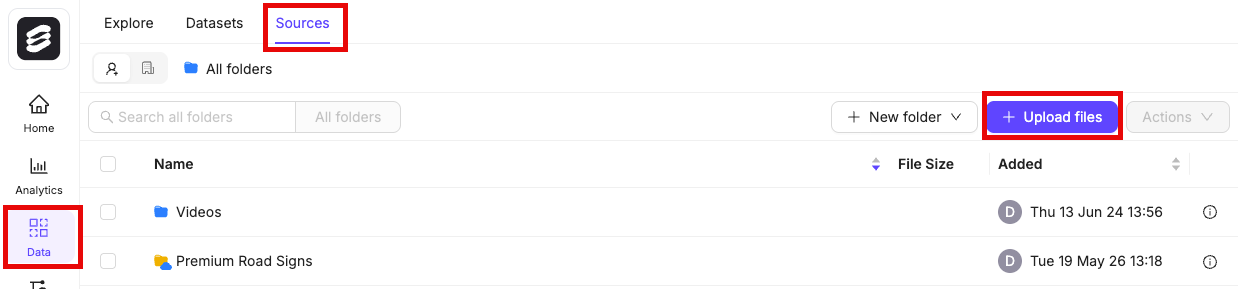
-
Click one of the following:
- Upload: Upload images, videos, and audio files.

- Batch images as: Upload image batches as image groups or image sequences.

- DICOM/NifTi: Upload DICOM or NifTi series.
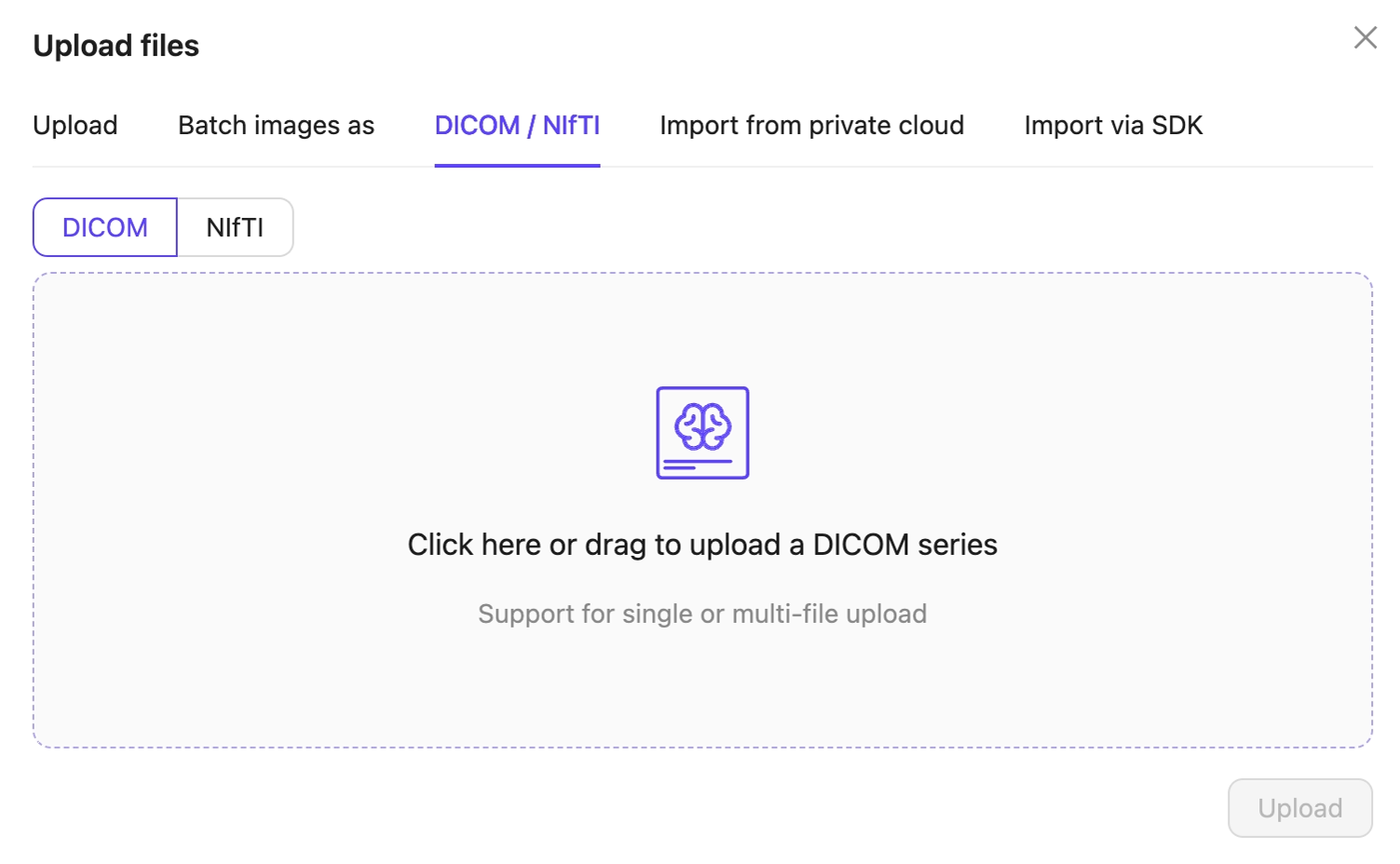
- Upload: Upload images, videos, and audio files.
- Click Upload after selecting your images or series. Your files upload into the Folder in Encord.
STEP 2: Create a Benchmark Project
The benchmark Project contains reference labels used to evaluate your annotators’ labels. These gold standard labels should be created by a trusted expert to ensure accurate assessment.
1
Create a Training Dataset
Create a Dataset containing tasks designed to establish ground truth labels. These files are used to generate ‘gold-standard’ labels against which annotator performance can be evaluated. Give the Dataset a meaningful name.
2
Create an Ontology
Create an Ontology to label your data. The same Ontology must be used in the Benchmark Project AND the Annotator Training Project.
3
Create the Benchmark Project
- Go to Annotate > Projects.
- Click the + New annotation project button to create a new Project.
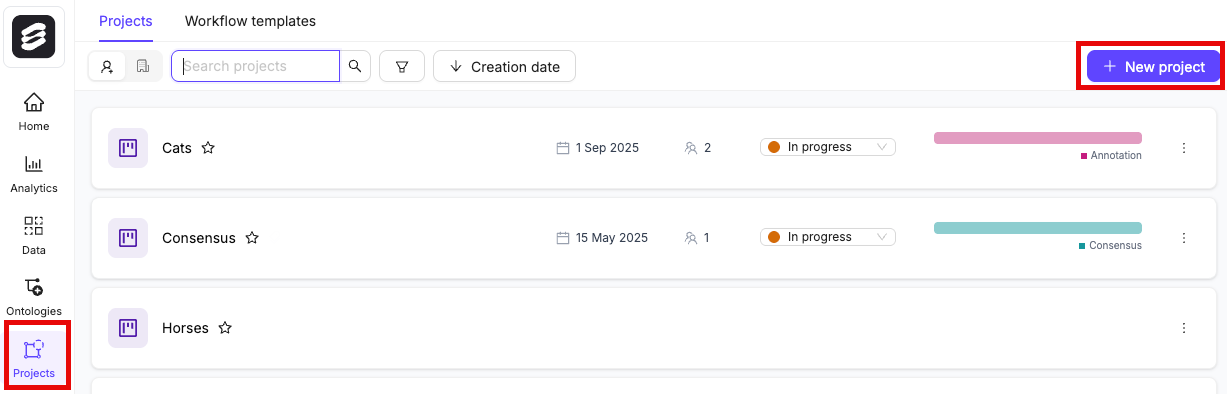
- Give the Project a meaningful title and description. For example “Benchmark Labels”.
- Click the Attach ontology button and attach the Ontology you created.
- Click the Attach dataset button and attach the Benchmark Dataset you created.

- Click Create project to finish creating the Project. You have now created the Project to establish ground-truth labels.
STEP 3: Create Annotator Training Projects
Create a Project where your annotation workforce labels data and is evaluated against benchmark labels.1
Create an Annotator Training Workflow Template
Create a Workflow template and give it a meaningful name like “Annotator Training”.Create the following Workflow template for your Annotator Training Projects. Documentation on how to create new Workflow templates can be found here.
2
Create Annotator Training Projects
You must create one Annotator Training Project per annotator. Repeat this step for each annotator.
- Go to Annotate > Projects.
- Click the + New annotation project button to create a new Project.
- Give the Project a meaningful title and description. For example “Annotator Training - Alex” for an annotator named Alex.
- Click the Attach ontology button and attach the Ontology you created. Attach the SAME Ontology you created in Step 2.2 for the Benchmark Project.
- Click the Attach dataset button and attach the training Dataset you created in Step 2.1.
- Click the Load from template button to attach the “Annotator Training” template you created in Step 3.1.
- Click Invite collaborators. Add the annotator you want to train in this Project to the annotation stage.
- Click Create Project to create the Project. You have now created the Project to train the selected annotator.
STEP 4: Annotator Training
Your annotators must now complete all tasks in the Annotator Training Project they are assigned to. Only tasks in the Complete stage are evaluated.Golden Label Reveal on Evaluation Tasks
Evaluation Projects that carry golden labels use a two-step submission flow to give annotators immediate feedback on their work. What are golden labels? Evaluation tasks store the correct answers alongside the annotator’s work under ontology attributes prefixed withgolden_ (for example, golden_detailed caption, golden_caption). These attributes are invisible during annotation, so annotators label the task without seeing the correct answers.
Two-step submission flow
When an annotator clicks Submit on an evaluation task that contains golden labels, the editor does not submit the task immediately. Instead:
- Read-only Correct rows appear beneath each timeline track, highlighted in green, showing the correct answers side by side with the annotator’s labels.
- A banner appears at the top of the editor reading: “Correct labels revealed — compare with your answers, then confirm to submit.”
- The annotator reviews their labels against the correct answers. Playback, zoom, and timeline seeking remain active so the annotator can compare answers in context.
- The annotator clicks Confirm & Submit in the banner to complete the task.
All editing interactions lock during the reveal — hotkeys, drag and resize of timeline ranges, caption input, the options panel, the label bank, and dispatch controls are all disabled. Only playback and timeline navigation remain active.
STEP 5: Evaluate Annotators
This example only evaluates Bounding Boxes.
iou_results.csv containing the results. The evaluation metrics used are Intersection over Union (IoU) and Class score.
- IoU (Intersection over Union): Quantifies the overlap between predicted labels and the ground truth. It ranges from 0 to 1: 1.0: Indicates a perfect overlap between the predicted label and the ground truth. 0.0: Indicates no overlap between the predicted label and the ground truth. Values between 0 and 1: Represent the percentage of overlap. For example, an IoU of 0.6 signifies that 60% of the predicted label area overlaps with the ground truth label area.
- Class Score (0 or 1): 1: The label was created using the correct class. 0: The label was created using the wrong class.
- Replace
<private_key_path>with the full path to your private access key. - Replace
<benchmark-project-id>with the id of your Benchmark Project. - Replace
<training-project-id>with the id of the Training Project you want to evaluate.