- Benchmark Project: This Project establishes the “ground-truth” labels, which serve as the benchmark for evaluating annotator performance.
- Production Project: In this Project, annotators generate the production labels. Annotator performance is scored against the ground-truth labels from the first Project.
STEP 1: Register Files with Encord
You must first register your files with Encord. This includes files that are used to establish ‘ground-truth’ labels, and your production data.Create a Cloud Integration
Create a Folder to Store your Files
- Navigate to Data > Files & Folders
- Click the + New folder button to create a new folder. Select the type of folder you want to create.
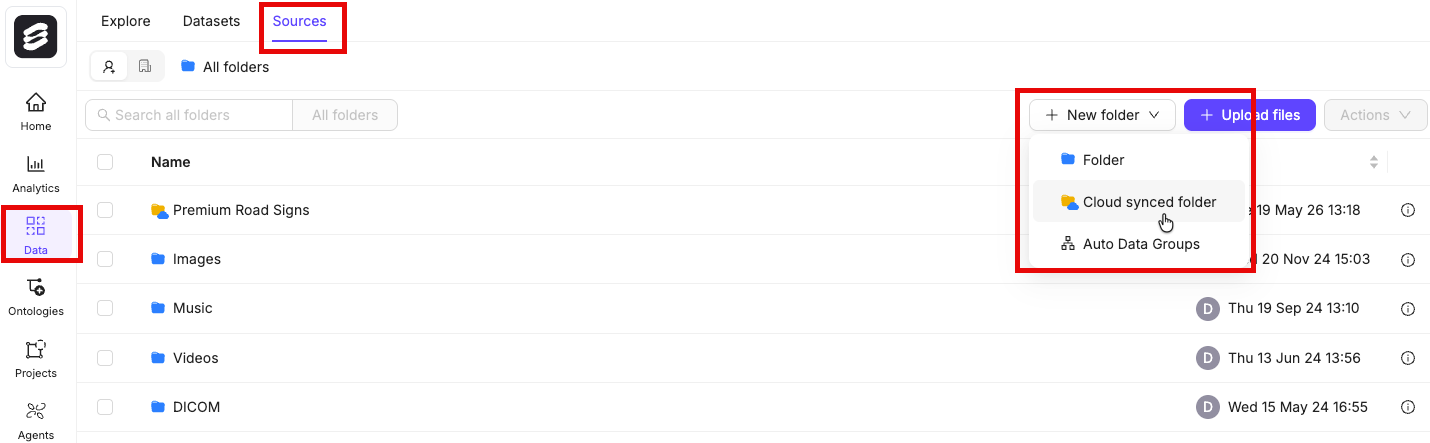
- Give the folder a meaningful name and description.
- Click Create to create the folder. The folder is listed in Files & Folders.
Create JSON file for Registration
- Up to 1 million URLs
- A maximum of 500,000 items (e.g. images, image groups, videos, DICOMs)
- URLs can be up to 16 KB in size
JSON Format
JSON Format
skip_duplicate_urls is set to true, all object URLs that exactly match existing images/videos in the dataset are skipped.JSON for AWS
JSON for AWS
Audio files
Audio files
Audio Files
The following is an example JSON file for uploading two audio files to Encord.- Template: Imports audio files with an Encord title.
- Audio Metadata: Imports one audio file with the
audiometadataflag. When theaudiometadataflag is present in the JSON file, we directly use the supplied metadata without performing any additional validation, and do not store the file on our servers. To guarantee accurate labels, it is crucial that the metadata you provide is accurate.
Text Files
Text Files
Single images
Single images
Single Images
For detailed information about the JSON file format used for import go here.The JSON structure for single images parallels that of videos.Template: Provides the proper JSON format to import images into Encord.Examples:- Data Imports the images only.
Image groups
Image groups
Image groups
For detailed information about the JSON file format used for import go here.- Image groups are collections of images that are processed as one annotation task.
- Images within image groups remain unaltered, meaning that images of different sizes and resolutions can form an image group without the loss of data.
- Image groups do NOT require ‘write’ permissions to your cloud storage.
- If
skip_duplicate_urlsis set totrue, all URLs exactly matching existing image groups in the dataset are skipped.
objectUrl_{position_number}).- Data: Imports the image groups only.
Image sequences
Image sequences
Image sequences
For detailed information about the JSON file format used for import go here.- Image sequences are collections of images that are processed as one annotation task and represented as a video.
- Images within image sequences may be altered as images of varying sizes and resolutions are made to match that of the first image in the sequence.
- Creating Image sequences from cloud storage requires ‘write’ permissions, as new files have to be created in order to be read as a video.
- Each object in the
image_groupsarray with thecreateVideoflag set totruerepresents a single image sequence. - If
skip_duplicate_urlsis set totrue, all URLs exactly matching existing image sequences in the dataset are skipped.
objectUrl_{position_number}).- Data: Imports the images groups only.
DICOM
DICOM
DICOM
For detailed information about the JSON file format used for import go here.- Each
dicom_serieselement can contain one or more DICOM series. - Each series requires a title and at least one object URL, as shown in the example below.
- If
skip_duplicate_urlsis set totrue, all object URLs exactly matching existing DICOM files in the dataset will be skipped.
.dcm file and does not have to be specific during the upload to Encord. - The first series contains only a single object URL, as it is composed of a single file.
- The second series contains 3 object URLs, as it is composed of three separate files.
- The third series contains 2 object URLs, as it is composed of two separate files.
DicomSeries file is created. This file represents the series file-set. Only DicomSeries are displayed in the Encord application. Multiple file types
Multiple file types
JSON for GCP
JSON for GCP
Audio files
Audio files
Audio Files
The following is an example JSON file for uploading two audio files to Encord.- Example 1 imports audio files with an Encord title.
- Example 2 imports one audio file with the
audiometadataflag. When theaudiometadataflag is present in the JSON file, we directly use the supplied metadata without performing any additional validation, and do not store the file on our servers. To guarantee accurate labels, it is crucial that the metadata you provide is accurate.
Text Files
Text Files
Single images
Single images
Single Images
For detailed information about the JSON file format used for import go here.The JSON structure for single images parallels that of videos.Template: Provides the proper JSON format to import images into Encord.Examples:- Data Imports the images only.
- Image Metadata: Imports images with image metadata. This improves the import speed for your images.
Image groups
Image groups
Image groups
For detailed information about the JSON file format used for import go here.- Image groups are collections of images that are processed as one annotation task.
- Images within image groups remain unaltered, meaning that images of different sizes and resolutions can form an image group without the loss of data.
- Image groups do NOT require ‘write’ permissions to your cloud storage.
- If
skip_duplicate_urlsis set totrue, all URLs exactly matching existing image groups in the dataset are skipped.
objectUrl_{position_number}).- Data: Imports the image groups only.
Image sequences
Image sequences
Image sequences
For detailed information about the JSON file format used for import go here.- Image sequences are collections of images that are processed as one annotation task and represented as a video.
- Images within image sequences may be altered as images of varying sizes and resolutions are made to match that of the first image in the sequence.
- Creating Image sequences from cloud storage requires ‘write’ permissions, as new files have to be created in order to be read as a video.
- Each object in the
image_groupsarray with thecreateVideoflag set totruerepresents a single image sequence. - If
skip_duplicate_urlsis set totrue, all URLs exactly matching existing image sequences in the dataset are skipped.
objectUrl_{position_number}).- Data: Imports the images groups only.
DICOM
DICOM
DICOM
For detailed information about the JSON file format used for import go here.- Each
dicom_serieselement can contain one or more DICOM series. - Each series requires a title and at least one object URL, as shown in the example below.
- If
skip_duplicate_urlsis set totrue, all object URLs exactly matching existing DICOM files in the dataset will be skipped.
.dcm file and does not have to be specific during the upload to Encord. - The first series contains only a single object URL, as it is composed of a single file.
- The second series contains 3 object URLs, as it is composed of three separate files.
- The third series contains 2 object URLs, as it is composed of two separate files.
DicomSeries file is created. This file represents the series file-set. Only DicomSeries are displayed in the Encord application. Multiple file types
Multiple file types
JSON for Azure
JSON for Azure
Audio files
Audio files
Audio Files
The following is an example JSON file for uploading two audio files to Encord.- Template: Imports audio files with an Encord title.
- Audio Metadata: Imports one audio file with the
audiometadataflag. When theaudiometadataflag is present in the JSON file, we directly use the supplied metadata without performing any additional validation, and do not store the file on our servers. To guarantee accurate labels, it is crucial that the metadata you provide is accurate.
Text Files
Text Files
Single images
Single images
Single Images
For detailed information about the JSON file format used for import go here.The JSON structure for single images parallels that of videos.Template: Provides the proper JSON format to import images into Encord.Examples:- Data Imports the images only.
- Image Metadata: Imports images with image metadata. This improves the import speed for your images.
Image groups
Image groups
Image groups
For detailed information about the JSON file format used for import go here.- Image groups are collections of images that are processed as one annotation task.
- Images within image groups remain unaltered, meaning that images of different sizes and resolutions can form an image group without the loss of data.
- Image groups do NOT require ‘write’ permissions to your cloud storage.
- If
skip_duplicate_urlsis set totrue, all URLs exactly matching existing image groups in the dataset are skipped.
objectUrl_{position_number}).- Data: Imports the image groups only.
Image sequences
Image sequences
Image sequences
For detailed information about the JSON file format used for import go here.- Image sequences are collections of images that are processed as one annotation task and represented as a video.
- Images within image sequences may be altered as images of varying sizes and resolutions are made to match that of the first image in the sequence.
- Creating Image sequences from cloud storage requires ‘write’ permissions, as new files have to be created in order to be read as a video.
- Each object in the
image_groupsarray with thecreateVideoflag set totruerepresents a single image sequence. - If
skip_duplicate_urlsis set totrue, all URLs exactly matching existing image sequences in the dataset are skipped.
objectUrl_{position_number}).- Data: Imports the images groups only.
DICOM
DICOM
DICOM
For detailed information about the JSON file format used for import go here.- Each
dicom_serieselement can contain one or more DICOM series. - Each series requires a title and at least one object URL, as shown in the example below.
- If
skip_duplicate_urlsis set totrue, all object URLs exactly matching existing DICOM files in the dataset will be skipped.
.dcm file and does not have to be specific during the upload to Encord. - The first series contains only a single object URL, as it is composed of a single file.
- The second series contains 3 object URLs, as it is composed of three separate files.
- The third series contains 2 object URLs, as it is composed of two separate files.
DicomSeries file is created. This file represents the series file-set. Only DicomSeries are displayed in the Encord application. Multiple file types
Multiple file types
JSON for OTC
JSON for OTC
Audio files
Audio files
Audio Files
The following is an example JSON file for uploading two audio files to Encord.- Template: Imports audio files with an Encord title.
- Audio Metadata: Imports one audio file with the
audiometadataflag. When theaudiometadataflag is present in the JSON file, we directly use the supplied metadata without performing any additional validation, and do not store the file on our servers. To guarantee accurate labels, it is crucial that the metadata you provide is accurate.
Text Files
Text Files
Single images
Single images
Single Images
For detailed information about the JSON file format used for import go here.The JSON structure for single images parallels that of videos.Template: Provides the proper JSON format to import images into Encord.Examples:- Data Imports the images only.
- Image Metadata: Imports images with image metadata. This improves the import speed for your images.
Image groups
Image groups
Image groups
For detailed information about the JSON file format used for import go here.- Image groups are collections of images that are processed as one annotation task.
- Images within image groups remain unaltered, meaning that images of different sizes and resolutions can form an image group without the loss of data.
- Image groups do NOT require ‘write’ permissions to your cloud storage.
- If
skip_duplicate_urlsis set totrue, all URLs exactly matching existing image groups in the dataset are skipped.
objectUrl_{position_number}).- Data: Imports the image groups only.
Image sequences
Image sequences
Image sequences
For detailed information about the JSON file format used for import go here.- Image sequences are collections of images that are processed as one annotation task and represented as a video.
- Images within image sequences may be altered as images of varying sizes and resolutions are made to match that of the first image in the sequence.
- Creating Image sequences from cloud storage requires ‘write’ permissions, as new files have to be created in order to be read as a video.
- Each object in the
image_groupsarray with thecreateVideoflag set totruerepresents a single image sequence. - If
skip_duplicate_urlsis set totrue, all URLs exactly matching existing image sequences in the dataset are skipped.
objectUrl_{position_number}).- Data: Imports the images groups only.
DICOM
DICOM
DICOM
For detailed information about the JSON file format used for import go here.- Each
dicom_serieselement can contain one or more DICOM series. - Each series requires a title and at least one object URL, as shown in the example below.
- If
skip_duplicate_urlsis set totrue, all object URLs exactly matching existing DICOM files in the dataset will be skipped.
.dcm file and does not have to be specific during the upload to Encord. - The first series contains only a single object URL, as it is composed of a single file.
- The second series contains 3 object URLs, as it is composed of three separate files.
- The third series contains 2 object URLs, as it is composed of two separate files.
DicomSeries file is created. This file represents the series file-set. Only DicomSeries are displayed in the Encord application. Multiple file types
Multiple file types
JSON for AWS Multi-Region Access Point
JSON for AWS Multi-Region Access Point
Import your Files

Import local data
Import local data
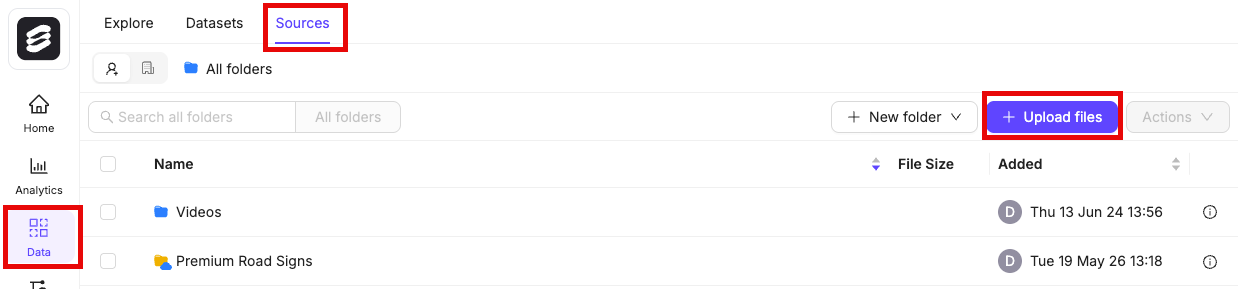
- Navigate to Data > Files & Folders in the Encord platform.
- Click into a Folder.
- Click + Upload files. A dialog appears.
-
Click one of the following:
- Upload: Upload images, videos, and audio files.

- Batch images as: Upload image batches as image groups or image sequences.

- DICOM/NifTi: Upload DICOM or NifTi series.
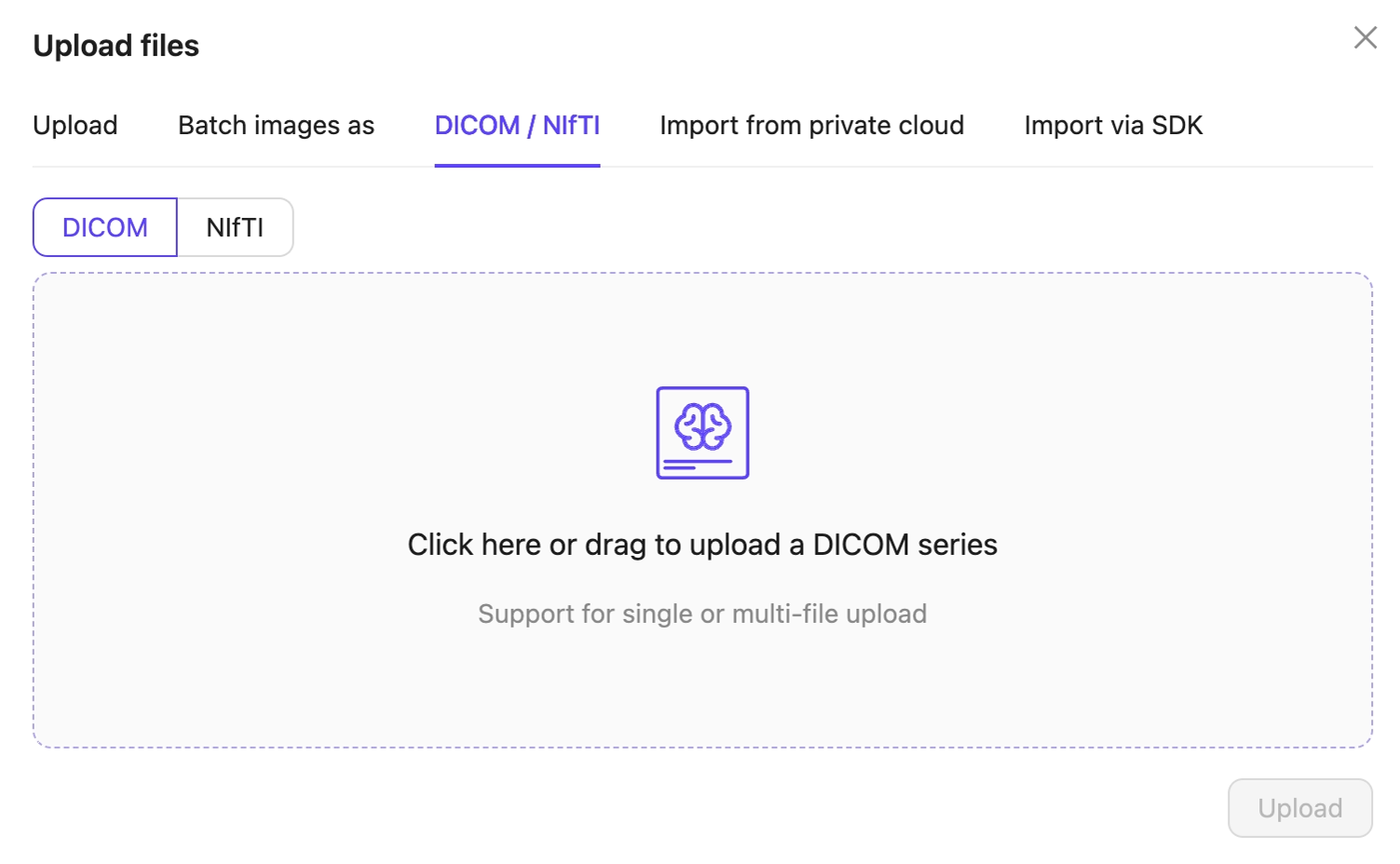
- Upload: Upload images, videos, and audio files.
- Click Upload after selecting your images or series. Your files upload into the Folder in Encord.
STEP 2: Create Benchmark Project
The Benchmark Project establishes ground truth labels.Create a Benchmark Dataset
Create an Ontology
Create a Workflow Template

Create the Benchmark Project
- In the Encord platform, navigate to Projects.
- Click the + New annotation project button to create a new Project.
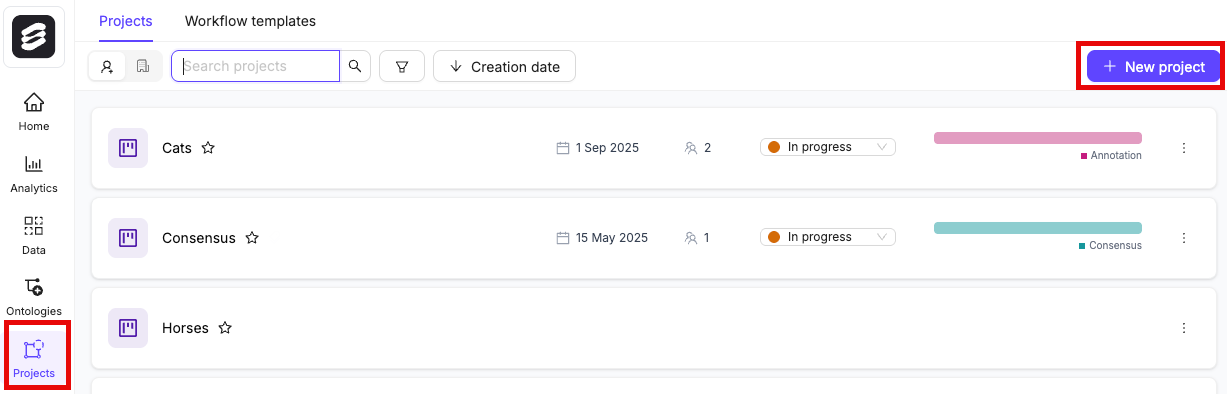
- Give the Project a meaningful title and description, for example “Benchmark Labels”.
- Click the Attach ontology button and attach the Ontology you created.
- Click the Attach dataset button and attach the Dataset you created.
- Click the Load from template button to attach the template you created in STEP 2.3.

- Click Create project to finish creating the Project. You have now created the Project to establish ground-truth labels.
STEP 3: Create Benchmark Labels
Complete the Benchmark Project created in STEP 2 to establish a set of ground truth labels for all data units in the Benchmark Dataset.STEP 4: Create Production Project
Create a Project where your annotation workforce labels data and is evaluated against benchmark labels.Create a Production Dataset
Create a Production Workflow Template
- A Custom Agent is used to route tasks depending on whether they originates in the Benchmark Dataset or the Production Dataset.
-
A script is will be added to the Consensus block of the Production Workflow to evaluate annotator performance.

Create The Production Project
- In the Encord platform, navigate to Projects.
- Click the + New annotation project button to create a new Project.
- Give the Project a meaningful title and description, for example “Benchmark QA Production Labels”.
- Click the Attach ontology button and attach the Ontology you created. Attach the SAME Ontology you created for the Benchmark Project.
- Click the Attach dataset button and attach the Benchmark AND the Production Datasets.
- Click the Load from template button to attach the “Benchmark QA Production Labels” template you created in STEP 4.2.
- Click Create Project to create the Project. You have now created the Project to label production data and evaluate annotators against the benchmark labels.
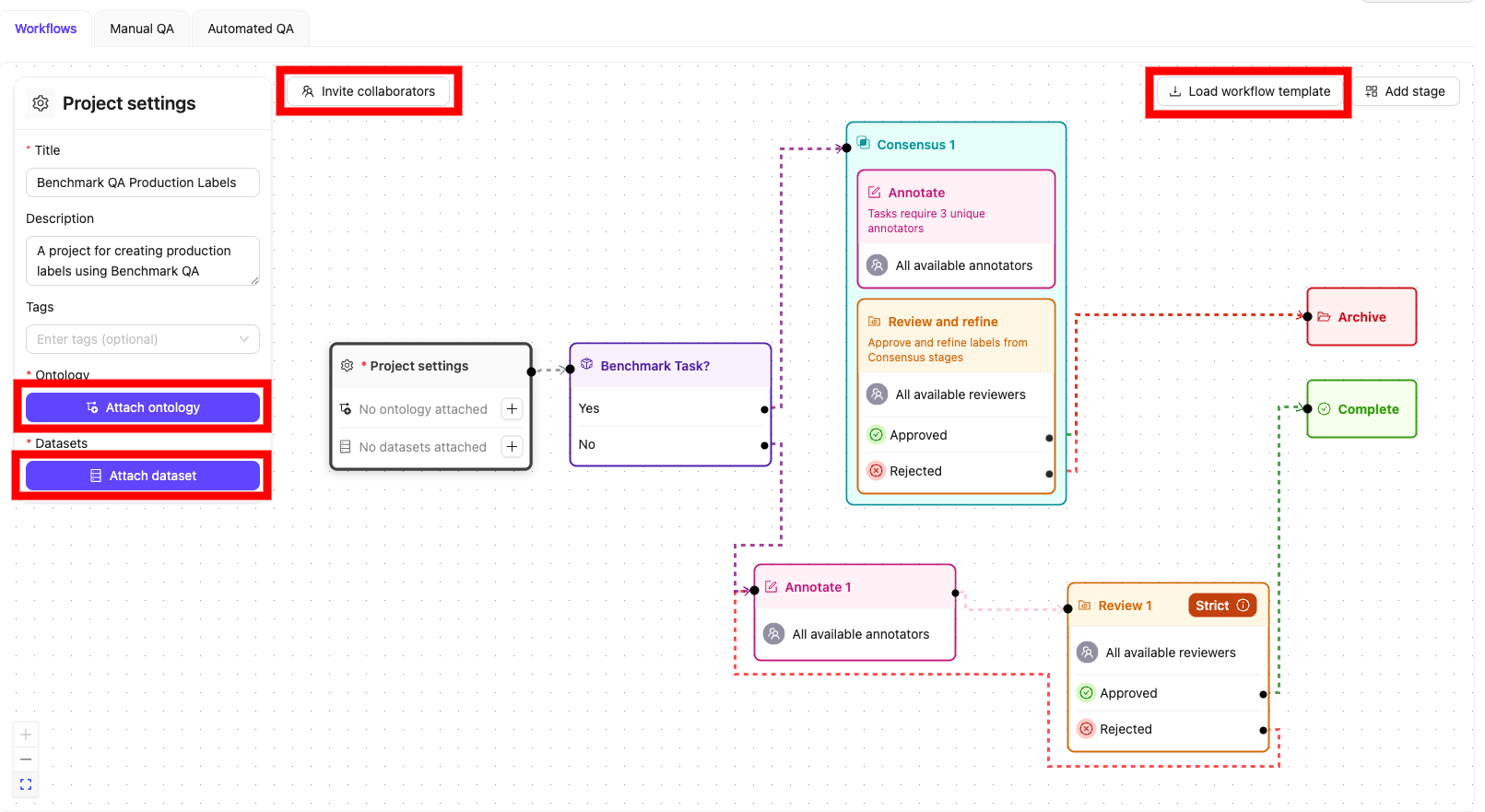
Create and run the SDK script for the Agent node
benchmark_routing.py script to check whether a data unit is part of the Benchmark Dataset, or the Production Dataset.- If a task is part of the Benchmark Dataset, the task is routed along the “Yes” pathway and proceeds to the Consensus 1 stage of the Production Project, where annotator performance is evaluated.
- If the task is not part of the Benchmark Dataset it is routed along the “No” pathway and proceeds to the Annotate 1 stage of the Production Project, where production data is labeled.
Create a script for the Review & Refine stage
sample_evaluation.py script for the Consensus 1 stage in the Production Project. The script compares the annotator’s labels in the Production Project with the ground truth labels established in the Benchmark Project.STEP 5: Create labels
Once your Production Project is set up, annotators can begin labeling the production data. Tasks from both the Benchmark Dataset and the Production Dataset are assigned to annotators. Their performance is then assessed based on how accurately they label the Benchmark tasks.STEP 6: Evaluate Annotator Performance
Run thesample_evaluation.py script created in STEP 4.5 to evaluate annotator performance.